Apache Flink零基础入门(二) 开发环境搭建、应用配置部署与运行
在上一篇中,我们介绍了Apache Flink的基本概念。本篇将带领你从零开始,搭建Flink开发环境,并完成一个简单应用的配置、部署与运行全流程。
一、开发环境搭建
一个完整的Flink开发环境需要以下几部分:
1. Java开发环境:Flink核心基于Java(也支持Scala)。请确保已安装JDK 8或11(推荐)。
`bash
# 检查Java版本
java -version
`
2. 构建工具:Maven配置
对于Java项目,我们使用Maven管理依赖。在~/.m2/settings.xml中,可以配置镜像仓库以加速依赖下载(国内用户建议配置)。
`xml
`
- 集成开发环境(IDE):推荐使用IntelliJ IDEA(社区版即可)或Eclipse,并安装好Maven插件。
4. Flink本地安装(可选,用于本地运行和测试)
从Flink官网下载对应版本的二进制包,解压即可。
`bash
# 解压后,可以启动一个本地单节点集群
./bin/start-cluster.sh
# 访问Web UI: http://localhost:8081
`
二、创建第一个Flink应用
我们将创建一个Maven项目,实现一个简单的单词计数(WordCount)应用。
1. 使用Maven Archetype创建项目
`bash
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.17.0 \
-DgroupId=com.learn.flink \
-DartifactId=flink-quickstart \
-Dversion=1.0 \
-Dpackage=com.learn.flink \
-DinteractiveMode=false
`
2. 项目核心依赖
查看生成的pom.xml,核心依赖是:
`xml
`
3. 编写WordCount示例代码
在src/main/java下创建StreamingWordCount.java:
`java
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamingWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 定义数据源(这里从Socket读取,用于测试)
DataStreamSource
// 3. 转换操作:切分、计数
SingleOutputStreamOperator
.flatMap(new Tokenizer())
.keyBy(value -> value.f0) // 按单词分组
.sum(1); // 对第二个字段(计数)求和
// 4. 输出结果(打印到控制台)
result.print();
// 5. 触发程序执行(流式作业必须调用)
env.execute("Streaming WordCount");
}
// 自定义函数,将一行文本拆分成(单词,1)的二元组
public static class Tokenizer implements FlatMapFunction
@Override
public void flatMap(String value, Collector
String[] words = value.toLowerCase().split("\\W+");
for (String word : words) {
if (!word.isEmpty()) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
}
`
三、应用的配置、部署与运行
模式一:本地IDE运行(开发调试)
1. 确保有一个Socket源。可以使用nc命令在终端开启一个服务:
`bash
# Linux/Mac
nc -lk 9999
# Windows可以使用其他工具,如netcat
`
- 在IDE中直接运行
StreamingWordCount的main方法。 - 在
nc终端输入几行英文句子,即可在IDE控制台看到实时单词计数输出。
模式二:本地Standalone集群运行
1. 打包应用:
`bash
cd flink-quickstart
mvn clean package -DskipTests
`
在target目录下生成JAR包(如flink-quickstart-1.0.jar)。
2. 提交到本地运行的Flink集群:
`bash
# 首先确保已启动本地集群(./bin/start-cluster.sh)
./bin/flink run \
-c com.learn.flink.StreamingWordCount \
/path/to/your/flink-quickstart-1.0.jar
`
- 通过Flink Web UI(http://localhost:8081)监控运行中的作业。
- 同样,通过向
localhost:9999发送文本数据来触发计算。
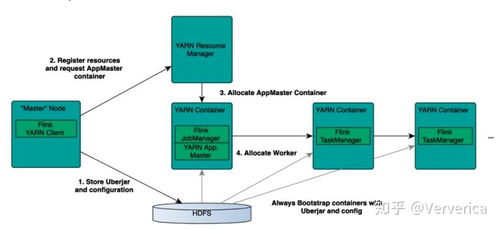
模式三:提交到生产集群(如YARN/K8s)
以YARN Session模式为例:
1. 启动YARN Session:
`bash
./bin/yarn-session.sh -tm 2048 -s 2
`
2. 提交作业:
`bash
./bin/flink run \
-yid
-c com.learn.flink.StreamingWordCount \
/path/to/your/flink-quickstart-1.0.jar
`
四、应用配置详解
Flink应用的配置主要通过ExecutionEnvironment或StreamExecutionEnvironment进行。
`java
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1. 设置并行度(全局)
env.setParallelism(4);
// 2. 开启Checkpoint(用于容错)
env.enableCheckpointing(10000); // 每10秒一次
// 3. 从配置文件读取配置(如flink-conf.yaml)
// 本地运行时,可加载自定义配置文件
Configuration config = new Configuration();
config.setString("taskmanager.memory.process.size", "2048m");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(config);`
还可以通过pom.xml中的<properties>和<profiles>来管理不同环境(开发/测试/生产)的构建配置。
###
至此,你已经完成了从环境搭建、项目创建、代码编写到应用部署运行的完整流程。关键步骤是:
- 使用Maven管理项目和Flink依赖。
- 理解
DataStream API的编程模式(创建环境、定义源、转换、输出、触发执行)。 - 掌握本地运行、本地集群提交和远程集群提交三种部署方式。
你可以尝试更复杂的数据源(如Kafka)、状态操作、窗口计算等,并深入探索Flink在实时数据处理领域的强大能力。
最新产品