ODPS技术架构解析及其在企业级大数据开发中的实践应用
在当今数据驱动的时代,大规模数据处理平台已成为企业数字化转型的核心引擎。阿里巴巴集团自主研发的ODPS(Open Data Processing Service,后更名为MaxCompute),作为其大数据计算的核心产品,凭借其强大的计算能力、稳定的服务性能以及完善的安全体系,在国内外众多企业的大数据实践中扮演着关键角色。本文将深入剖析ODPS的技术架构,并结合实际开发经验,探讨其在企业级应用中的实践路径。
一、ODPS核心技术架构剖析
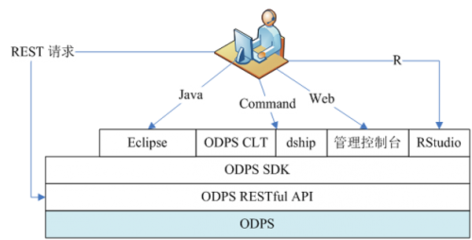
ODPS的架构设计遵循了经典的分布式系统理念,旨在提供海量数据的存储与计算能力。其核心可划分为四大层次:
- 接入层:作为用户与平台的交互入口,提供多种接入方式,包括Web控制台、命令行工具(odpscmd)、以及丰富的SDK(支持Java、Python、PHP等),满足不同场景和开发习惯的需求。它集成了完善的身份认证与权限管理(RAM)体系,确保数据访问安全。
- 逻辑层:这是ODPS的“大脑”,负责解析和优化用户提交的任务。主要包括:
- SQL引擎:兼容标准SQL语法(并进行了大量扩展),将用户的SQL查询语句编译成高效的分布式执行计划。
- MapReduce/Graph/Spark引擎:提供更灵活的编程模型,用于处理复杂的迭代计算、图计算和流处理等场景。
- 优化器:基于代价的优化器(CBO)对执行计划进行深度优化,包括谓词下推、分区裁剪、Join优化等,极大提升计算效率。
- 计算与调度层:该层负责将逻辑执行计划转化为物理任务,并进行分布式调度与执行。其核心是伏羲(Fuxi)分布式调度系统,它统一管理着庞大的集群资源,能够实现数万级计算节点的协同工作,自动处理节点故障,保证任务的稳定运行和高资源利用率。
- 存储层:基于自研的盘古(Pangu)分布式文件系统构建。盘古采用多副本机制保障数据的高可靠性,并针对大数据场景做了大量优化,支持高效的数据压缩和列式存储(ORC、Parquet格式),为上层计算提供高吞吐、低延迟的数据读写能力。数据以“项目(Project)-表(Table)-分区(Partition)”的三级结构进行组织,便于管理和高效查询。
这种分层解耦的架构,使得ODPS具备了极佳的弹性扩展能力和稳定性,能够从容应对EB级别的数据量和复杂的计算任务。
二、ODPS在企业级大数据开发中的核心应用实践
基于其强大的技术架构,ODPS在企业数据仓库建设、数据湖分析、机器学习及数据挖掘等领域有着广泛应用。以下结合CFANZ社区及业界常见实践,几个关键应用场景:
- 构建企业级数据仓库(EDW):ODPS是构建云端数据仓库的理想选择。企业可以将来自各业务系统(如交易日志、用户行为、ERP等)的数据,通过数据集成工具(如DataWorks的数据同步)定时或实时地汇聚到ODPS中。利用其SQL能力,可以高效地进行数据清洗、维度建模(如星型模型、雪花模型),形成主题明确、结构清晰的数据集市和汇总层,最终为BI报表、即席查询提供统一、可信的数据服务。
- 大规模日志分析与用户画像:对于互联网企业产生的海量用户行为日志,ODPS的批处理能力优势明显。通过编写SQL或MapReduce程序,可以快速完成PV/UV统计、路径分析、漏斗模型计算等。结合其UDF(用户自定义函数)和UDAF(用户自定义聚合函数)功能,可以灵活地构建复杂的用户标签体系,实现精准的用户画像,为个性化推荐和精准营销提供数据支撑。
- 机器学习与数据挖掘平台:ODPS集成了PAI(Platform of Artificial Intelligence) 机器学习平台,提供了从数据处理、特征工程、模型训练到在线预测的全流程支持。数据科学家可以在ODPS中直接使用SQL或PyODPS进行特征提取,然后利用PAI提供的丰富的算法组件(包括传统统计模型和深度学习框架)进行模型训练。训练好的模型可以一键部署为在线服务,形成完整的数据智能闭环。
- 成本与性能优化实践:在企业应用中,成本控制与性能调优至关重要。常见的ODPS优化实践包括:
- 数据层面:合理设计表分区和生命周期,及时删除过期数据;选择合适的数据压缩格式和列类型;对小表使用“广播”优化等。
- 计算层面:避免使用
SELECT *,明确指定所需列;优化Join条件,优先使用分区键;利用CBO的统计信息进行查询重写;对复杂作业进行分步骤计算,中间结果使用临时表缓存。
- 任务调度:利用DataWorks等工具实现依赖关系的可视化编排,错峰执行高资源消耗任务,提升整体集群利用率。
三、与展望
ODPS作为经过阿里巴巴超大规模业务场景锤炼的大数据平台,其技术架构成熟、生态完善、服务稳定。采用ODPS不仅可以快速获得处理海量数据的能力,还能借助其上层工具链(如DataWorks、Quick BI)快速构建端到端的数据解决方案。
随着云原生和湖仓一体概念的深入,ODPS也在持续进化,例如加强实时计算能力(与Flink、Hologres融合),支持更多开源生态格式(如Iceberg),以及提供更细粒度的资源组隔离与弹性计费模式。ODPS将继续降低大数据技术的使用门槛,赋能更多企业挖掘数据价值,驱动智能决策与业务创新。
(本文由Andy@根据ODPS公开技术资料及社区开发实践经验,发布于CFANZ社区,旨在进行IT技术分享与交流。)